You should benchmark LLMs
one man’s AI slop is another man’s metric pop - Gwern

What are benchmarks?
Benchmarks are a standardized way of measuring LLMs’ capabilities1 on various NLP problems by asking them to solve a set of tasks which form a dataset called a benchmark. Besides the tasks, you can also find evaluation metrics such as accuracy, F1 score, BLEU score etc., related to the questions we are asking LLMs to solve.
Traditionally, benchmarks were developed exclusively by AI research labs, academic institutions, or industry companies, as a method to track progress in the field and at the same time assess the economic implications of developing these models. For example, this includes understanding how many gigawatts are necessary to train the models, and the computing power required to answer my tasks in under 5 minutes.
Why do we use benchmarks?
In general, we want to use benchmarks on a diverse range of models and check how well these LLMs are able to solve problems that were not present in their pre-training data. In other words, benchmarks measure how well they generalize their knowledge in order to solve novel or hard problems.
Comparing AIs against each other based on standardized tests helps researchers understand a model’s weaknesses and directs them towards a specific area of knowledge where they might have to fine-tune the LLMs. Although making them better on a specific set of tasks might imply the empirical assumption that they might get better in general, most of the time that’s not the case.
Another important observation we can collect from benchmarking is the assessment of guardrails’ effectiveness. This helps us in mitigating risks and trying to avoid potential tragedies, while understanding how models are using reward hacking or broader misalignment.
Why Kaggle Community Benchmarks are a breath of fresh air
With the recent implementation of Community Benchmarks, Kaggle helped add a foundational brick to the democratization of AI development that ultimately affects a tremendous number of people! Empowering users to produce evals the same way the research labs are doing it2, while being on a free platform, is a great start.
Of course, the computation ecosystem is not as broad as what the research labs have access to, but it still enables you to develop unique tasks which might signal some important flaws the models have. You can view it this way: you are doing the job of an open-source contributor with the final goal of ensuring the most important technology developed in our lifetime will head in the right direction. I think this is an important step towards leveling the playing field between private companies that build these models and the community that should have a say about how the technology should be developed.
My first benchmark
The type of benchmark I tried to build was a Reasoning Benchmark.
A Reasoning Benchmark is a kind of benchmark where you try to create tasks in the question-answer format intended to be more complex than standard question answering.
My source of inspiration was an old math puzzle book that I have in my library. In it, I found a series of problems written by a mathematician called Lewis Carroll. The set of questions were about deductive reasoning, and they were composed of a set of premises (P1, P2... Pn) which varied from problem to problem in length, and I thought that this would make a great assessment of the LLMs’ COT (Chain of Thought).
More precisely, the benchmark tries to evaluate models’ ability to:
Parse natural language premises into logical relationships.
Identify and apply contrapositions (if A implies B, then not B implies not A).
Chain multiple logical steps without losing track or making errors.
Handle negations, double negatives, and existential quantifiers.
Construct a proof by contradiction.
It was fairly easy to evaluate the models because each task had only one correct answer3.
Task framework
In order to make the benchmark objective and easily reproducible across potential new additions, I constructed a framework4 for each task that follows this format:
The prompt is identical for each task and is presented in a zero-shot scenario.
A standard keyword check for the response. If the filter fails, it means the model didn’t understand the basic scenario presented.
An LLM acts as a judge that evaluates the response against the criteria:
Correct conclusion: does the stated answer match the expected answer?
Valid reasoning chain: are the intermediate steps correct and properly ordered?
No logical errors: are there any incorrect deductions or fallacies?
Closing thoughts
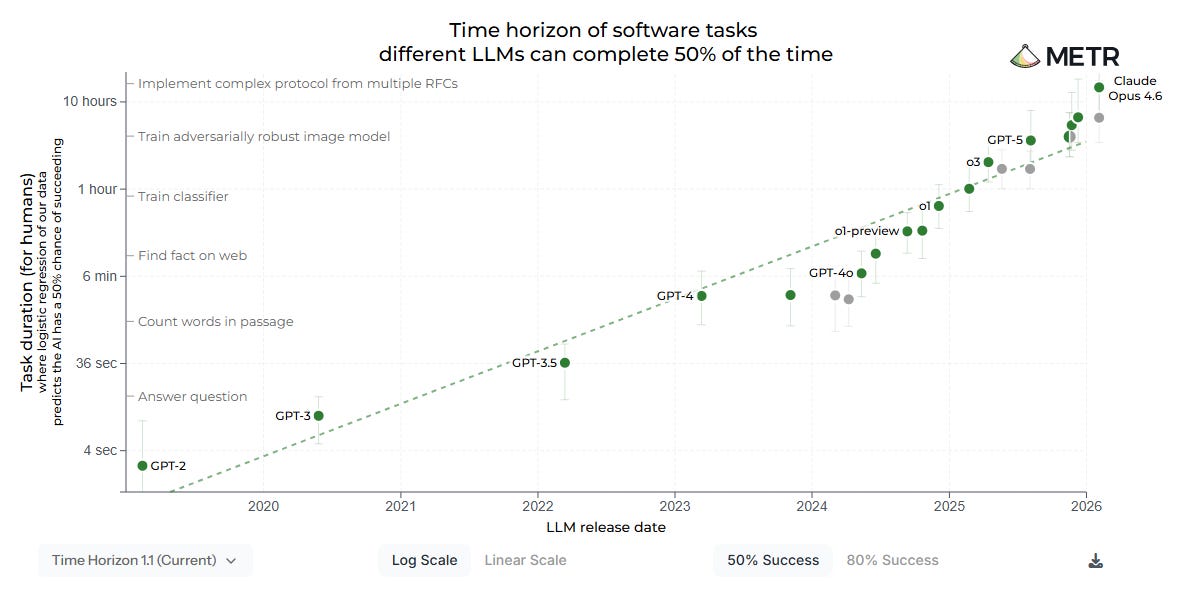
Not all research labs are inherently evil or try to provide benchmarks that only plot the performance of the models going up every 6 months5. For example, METR is evaluating models for companies like OpenAI and Anthropic without making these hype marketing charts.
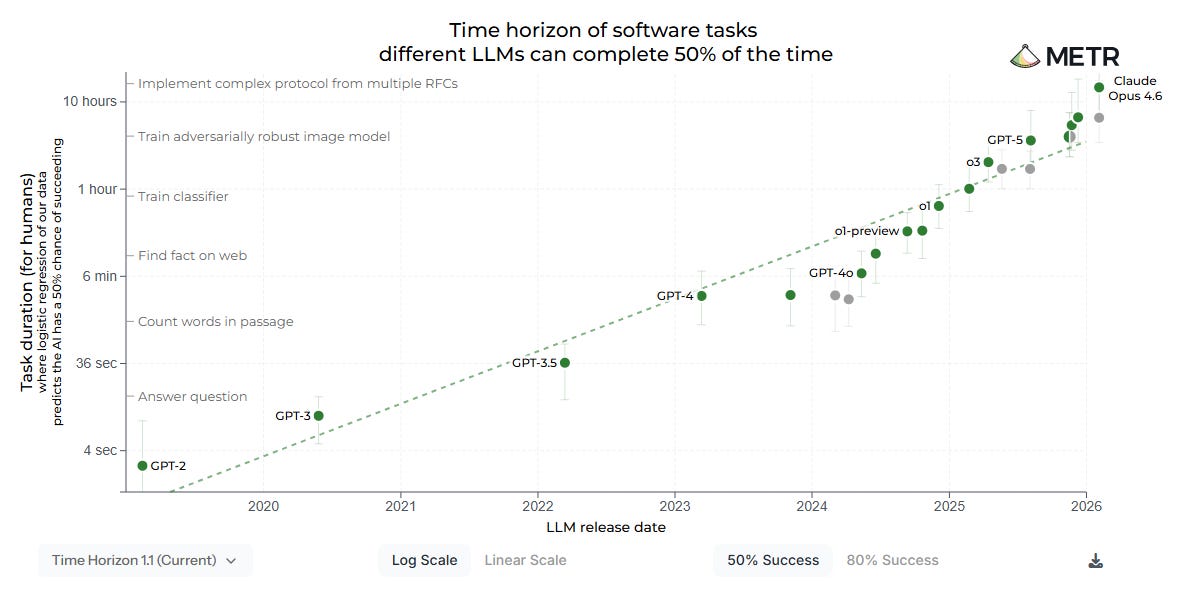
Time horizon of software tasks different LLMs can complete 50% of the time One of their most popular charts and research papers, Task-Completion Time Horizons of Frontier AI Models6, tells us the maximum duration and complexity of a task an AI can independently complete (e.g., executing a cybersecurity or software engineering task that would typically take a human engineer several hours to solve). That way you can get an idea of how one of these models might perform in these specific fields if treated as new employees that have no context, just some well-defined tasks given to them.
Benchmarks still have a lot of flaws and I think the open-source type of thinking would help us reduce some of the current problems (that’s why I’m so positive about what Kaggle has done). Some approaches7 that we as the community should look into are:
AI audits
Fine version control
Peer review
Community support
We should care more. Currently, the most hyped benchmarks are heavily targeted towards productivity and coding tasks, which makes sense considering that the people creating them make a living out of it. But as a community, I think this is our chance to increase the diversity of our expectations8 towards what an LLM can help us with. Building benchmarks tailored to our needs, that go further than programming and heavily punish mode-collapse. This way the private companies will start noticing people’s real needs, and maybe our thinking won't feel flattened or hollowed out next time writing to a chatbot.